BigBikeLoc : prédire la disponibilité des vélos Vélo’v et orchestrer tout le flux
Dans les projets de mobilité urbaine, combiner modèles de machine learning, API de production et outils métier (alertes, formulaires, supervision) devient vite lourd à déployer et à maintenir. BigBikeLoc est un écosystème modulaire centré sur la prédiction multi-horizon de la disponibilité des vélos du réseau Vélo’v (Lyon) : il relie un pipeline d’entraînement, une API d’inférence, un frontal utilisateur, l’automatisation (n8n), la génération de contenu par LLM, l’envoi d’e-mails, la collecte de feedback et le suivi de la dérive des données, le tout orchestré par Docker et un réseau commun.
Contexte académique et équipe
Le projet a été réalisé dans le cadre du dernier semestre à Polytech Lyon, en équipe avec Agathe Minguet, Simon Morier, Timothé Longuet, Clément Ruchon et Ismail El Mouaddab.
Technologies principales
- Python : cœur du ML et du backend (entraînement, features, API, tests pytest).
- FastAPI : API REST d’inférence, schémas Pydantic, documentation OpenAPI (
/docs). - LightGBM : modèles par horizon (1 h, 3 h, 6 h, 12 h, 24 h), export joblib et alignement strict des features sur
model.feature_name_. - pandas / Parquet : données tabulaires, profil same-slot, artefacts versionnés.
- Hugging Face Datasets : chargement et fusion des jeux (Vélo’v, météo, etc.).
- Docker & Docker Compose : services conteneurisés, volumes partagés
shared/artifactsetshared/data. - Streamlit : interface web du frontal (port 8501 dans l’orchestration décrite).
- n8n : workflows (webhooks, chaînage vers Ollama et envoi de mails).
- Ollama : modèle TinyLlama pour rédiger le corps des e-mails à partir des prédictions.
- Evidently : suivi / monitoring ML sur les données partagées avec l’API (port 8085).
Architecture
Le dépôt s’organise en plusieurs composants (souvent des dépôts Git distincts dans la pratique, mais regroupés sous un même workspace) :
BBL_dataset_training — producteur d’artefacts ML
Pipeline : chargement, nettoyage, features (lags, rolling, temporel, same-slot, encodage des stations), construction du dataset multi-horizon, entraînement spécialisé par horizon, export versionné sous shared/artifacts/ (registry.json, current/, versions/<version>/). Un worker de réentraînement surveille des fichiers de déclenchement, relance l’entraînement et active une nouvelle version sans écraser l’historique.
BBL_FastAPI — API d’inférence et boucle de feedback
Charge la version active via registry.json, reconstruit les features à l’inférence (feature_builder), sert POST /predict, journalise les prédictions en JSON Lines, reçoit la vérité terrain via POST /feedback, peut déclencher un réentraînement par fichier trigger (seuil de feedbacks, etc.), et recharge les modèles sans redémarrage complet (reload_if_needed, POST /admin/reload-model). Expose aussi la santé du service et des routes stations (liste, détail, recherche par nom).
BBL_Scripts — orchestration
Scripts start-all / stop-all (Linux, Windows) : création des dossiers partagés, réseau Docker BBL-network, ordre de démarrage des stacks (n8n, API, front, Evidently, etc.), vérifications (ports, Ollama, import de workflow n8n).
BBL_n8n — automatisation et notifications
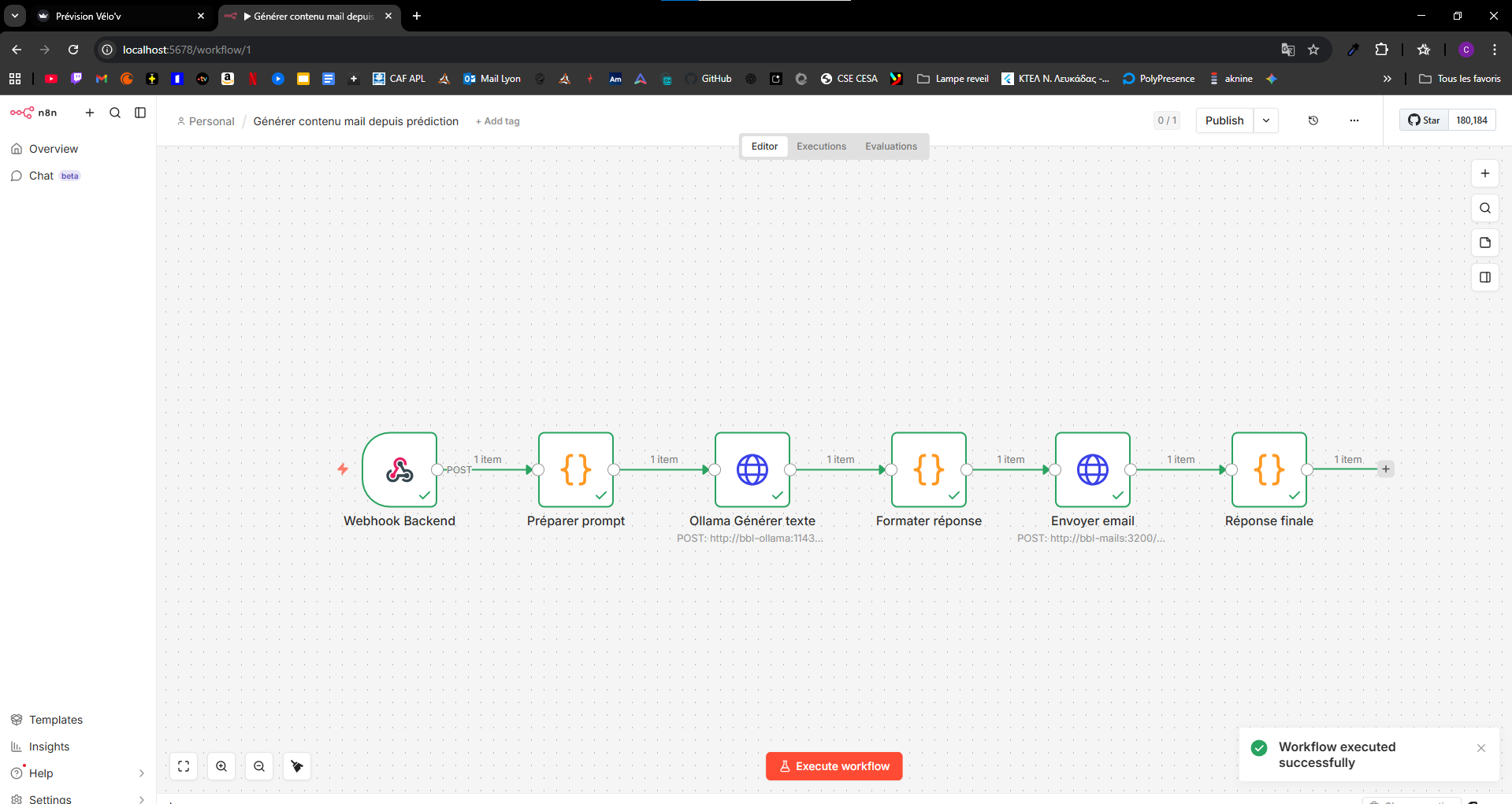
n8n, service bbl-mails (SMTP), bbl-forms (formulaires / feedback côté web), Ollama. Un workflow typique : webhook → préparation du prompt → Ollama → formatage → envoi d’e-mail → réponse JSON (contenu_mail, email_sent, etc.).
BBL_front — application Streamlit
Application Streamlit pour consommer l’API côté utilisateur.
BBL_Evidently — monitoring
Tableaux de bord de monitoring sur les données exposées dans les volumes partagés avec l’API.
Les volumes shared/artifacts et shared/data font le lien contractuel entre entraînement, inférence, logs de production, feedbacks et triggers de réentraînement, sans coupler le code du trainer à celui de l’API par des imports croisés.
Fonctionnalités clés
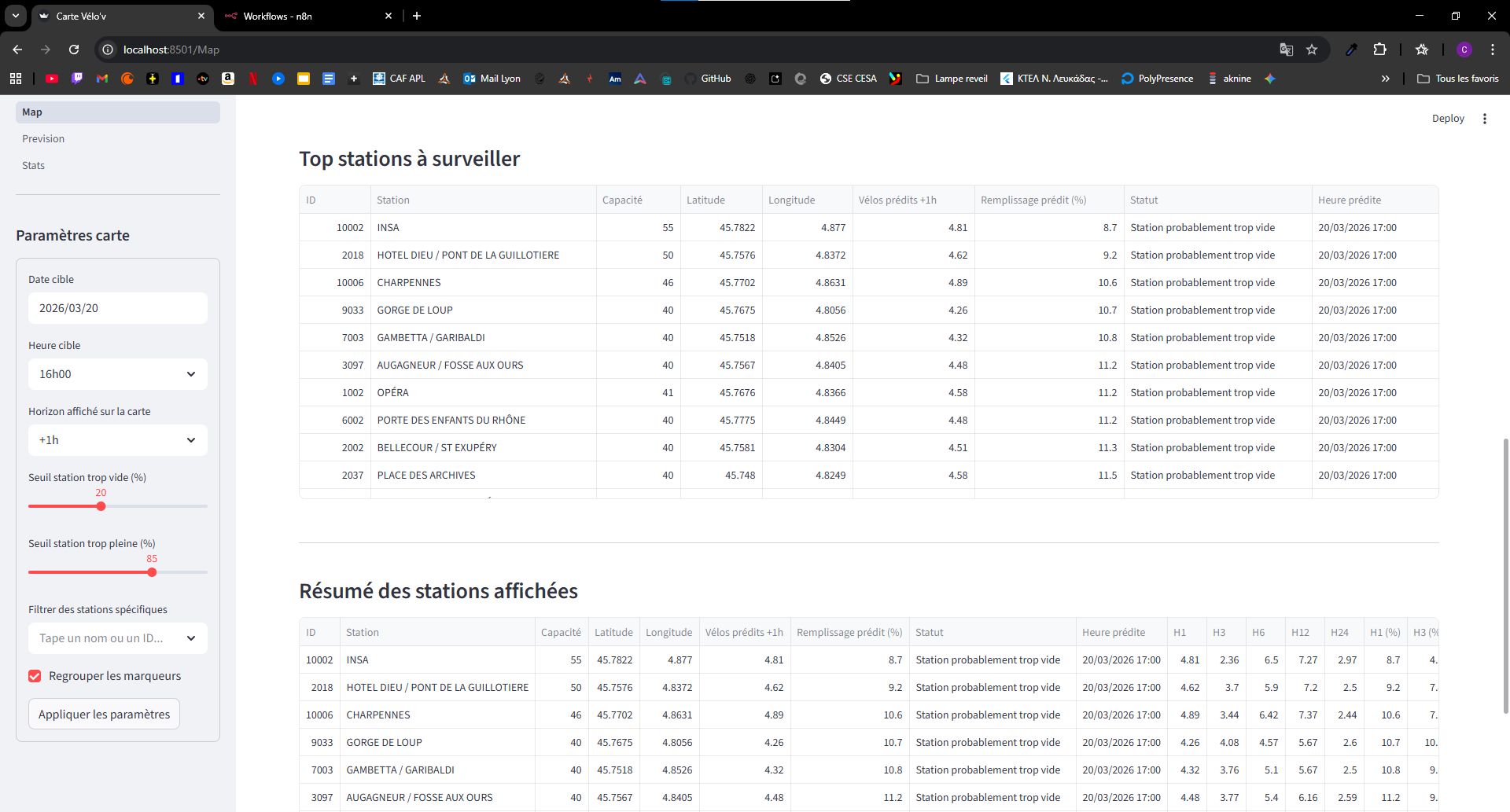
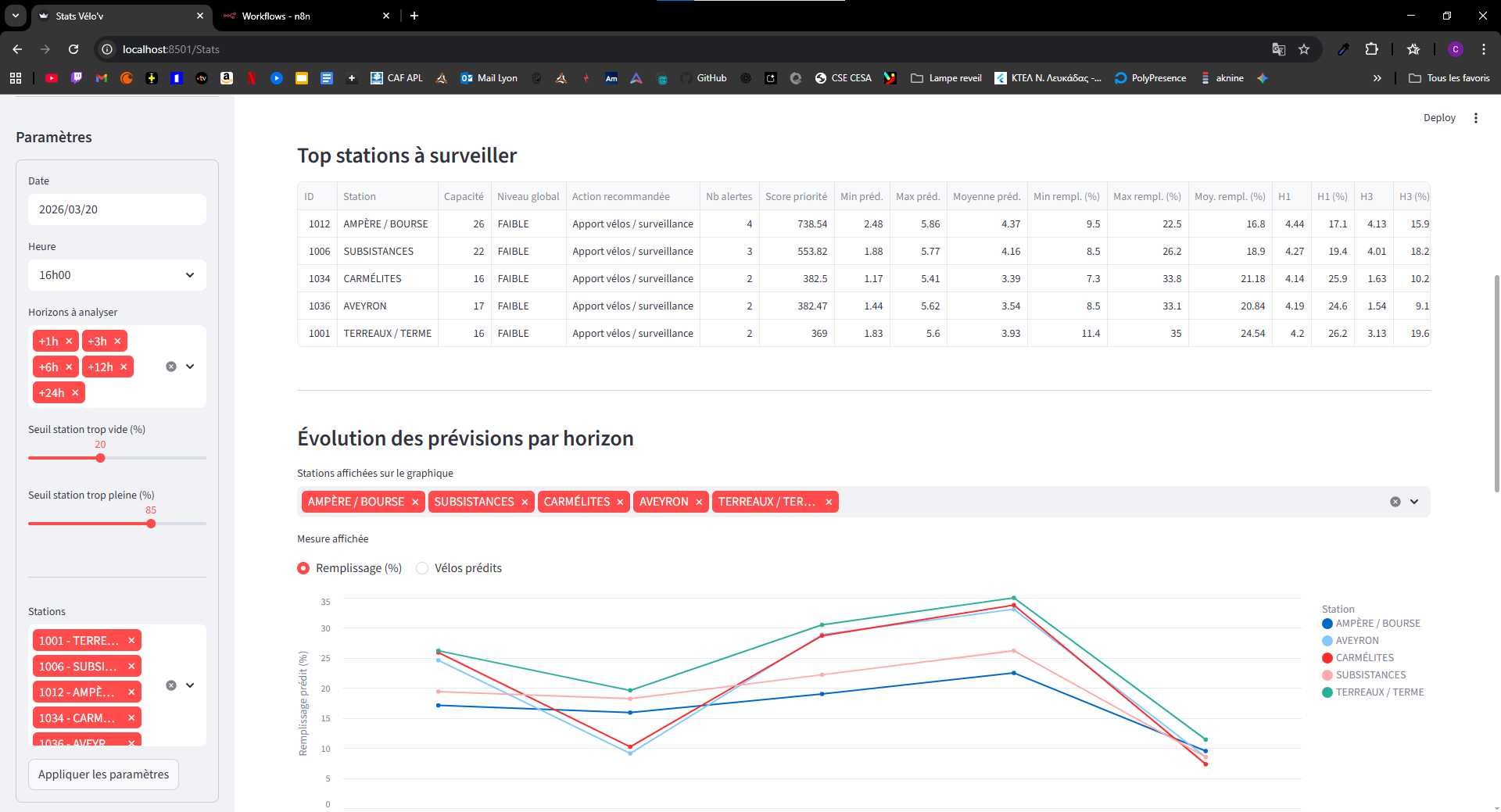
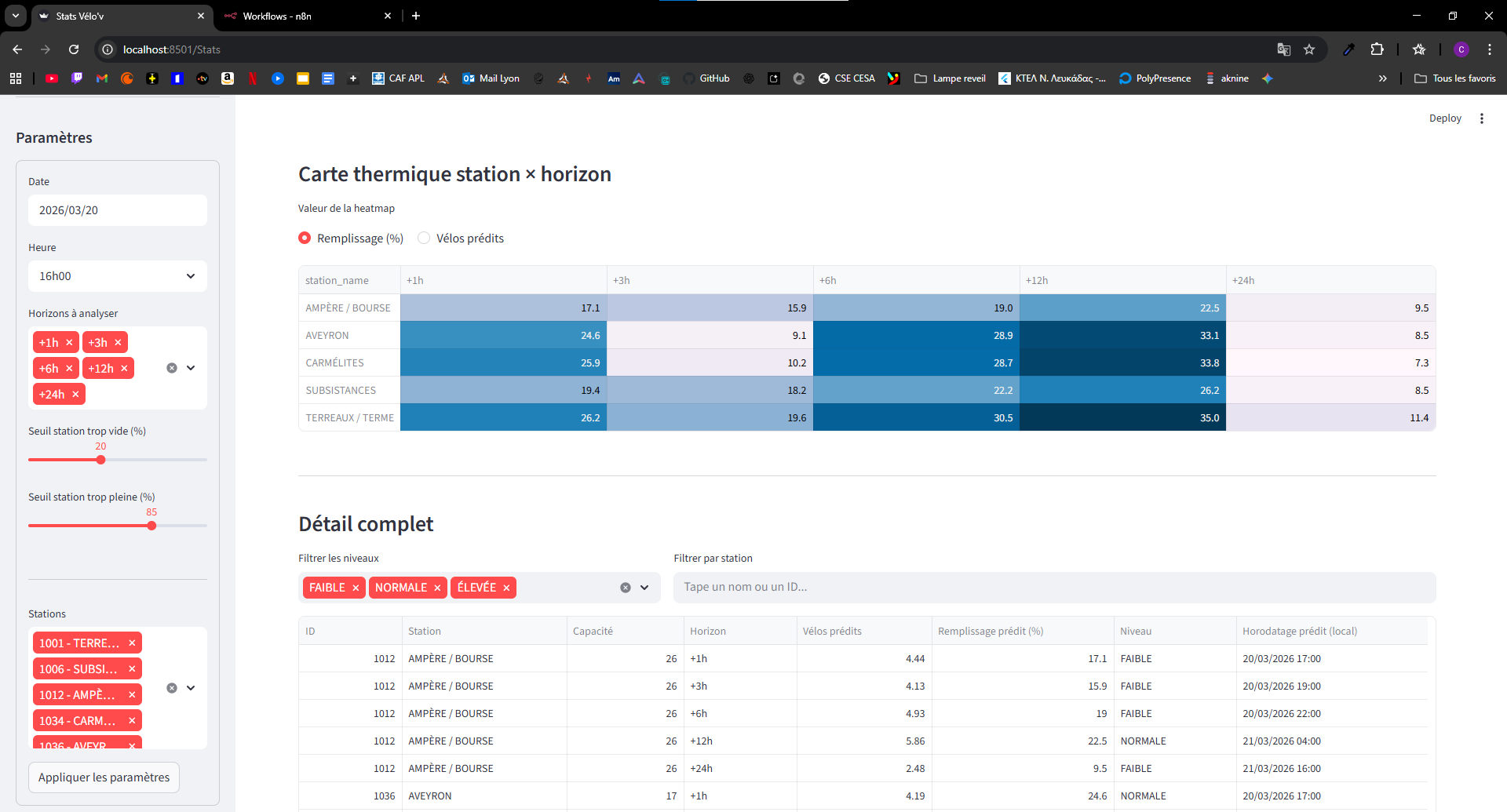
- Prédiction multi-horizon pour une station et un instant donnés, à partir d’un historique horaire de disponibilité.
- Versionnement explicite des modèles : chaque publication est un dossier de version complet ;
registry.jsonest la source de vérité de la version active. - Journalisation production : une ligne JSONL par horizon prédit, traçabilité
request_idetmodel_version. - Boucle fermée feedback → réentraînement : accumulation des retours, seuils configurables, déclenchement asynchrone du worker d’entraînement, puis rechargement côté API.
- Découverte des stations Vélo’v : mapping ID / nom officiel (centaines de stations), recherche par libellé.
- Notifications intelligentes : chaînage n8n + LLM pour personnaliser le texte des e-mails à partir des prédictions.
- Formulaires et webhooks pour intégrer le flux métier (collecte, tests, démonstrations).
- Supervision ML avec Evidently sur les données partagées.
- Démarrage unifié via scripts d’orchestration et réseau Docker dédié pour la résolution de noms entre conteneurs (
http://api:8000,http://bbl-n8n:5678, etc.).
Développement et défis
Mettre en cohérence deux mondes (repo d’entraînement et repo API) impose un contrat d’artefacts disque et un contrat de payloads API stricts : ordre des features, horizons supportés, fichiers obligatoires à chaque version, pas de réentraînement dans le thread HTTP. La compatibilité avec Insomnia / Postman ou tout client REST est naturelle grâce à FastAPI et aux schémas documentés. L’intégration n8n, Ollama et SMTP ajoute la gestion des secrets (.env), des URLs de webhook (test vs production) et de la robustesse lorsque l’envoi d’e-mail est optionnel ou en échec.
Accès au projet et captures
Le code vit sous le workspace BigBikeLoc : chaque sous-dossier (BBL_FastAPI, BBL_dataset_training, BBL_n8n, BBL_Scripts, BBL_front, BBL_Evidently) dispose de son README et, pour les parties ML/API, d’une documentation détaillée (doc/ARCHITECTURE.md, doc/SYSTEM.md, guides de tests). Pour une démo locale : lancer Docker, exécuter le script start-all adapté à l’OS, puis ouvrir les URLs documentées (API sur le port 8000, Streamlit 8501, n8n 5678, formulaires 3100, Evidently 8085).